지난번 CNN(Convolutional Neural Network)의 개념과 컨볼루션(Convolution)에 대해 학습해 보았고, 1 채널의 컨볼루션 연산 실습 코드를 통해 연산이 어떻게 이루어지는지를 학습해 보았다.
하지만 1채널은 흑백의 이미지를 의미하는 것이라 실제 상황과 맞는다고 할 수 없기에 이번에는 다중 채널 컨볼루션을 통해 RGB 입력에 대해 여러 필터를 사용하는 과정을 비롯해 중요한 정보는 취하고, 중요하지 않은 정보는 버린다고 표현되는 풀링(Pooling), CNN 아키텍처 구조 설계 등에 대해 정리하며 학습해 볼 것이다.
예제 코드를 함께 작성하고 이해해 보는 것을 통해 개념을 이해했는지 확인해 볼 예정이다.
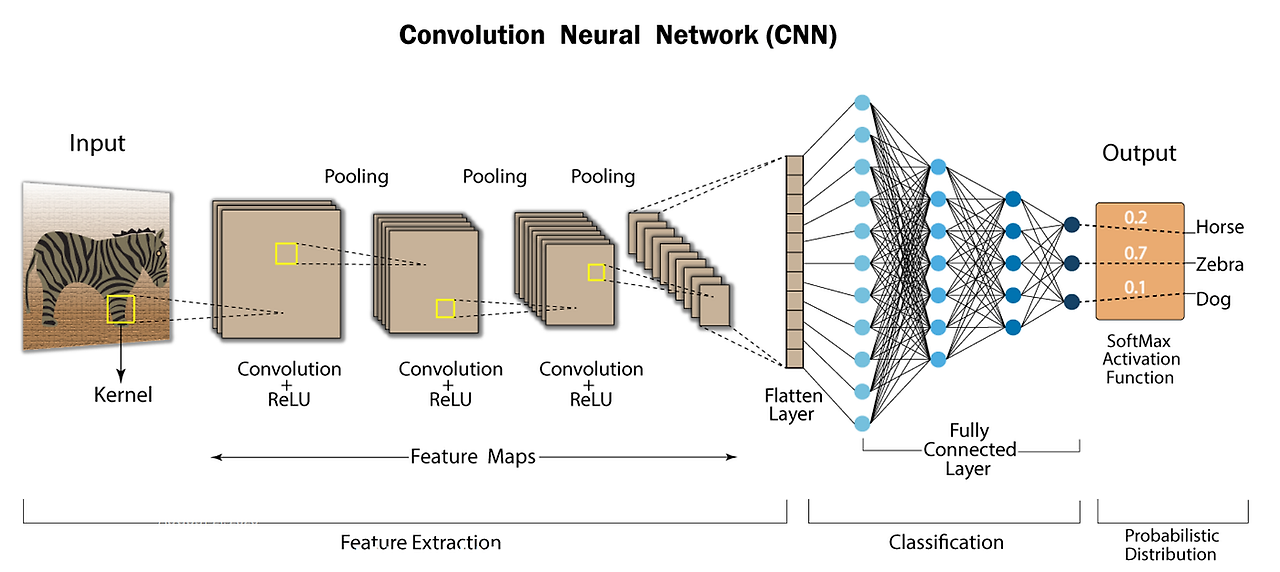
✅ 다중 채널 컨볼루션
CNN이 컬러 이미지를 처리할 때는 각 필터가 모든 채널(R, G, B) 을 동시에 보고, 그 결과를 합산해서 하나의 출력 값을 만든다.
🔹 시각적 이해
예를 들어, 입력이 (5, 5, 3)이라면:
- 각 필터는 (3, 3, 3) 구조를 가짐 → 3 채널에 대해 각각 가중치를 갖는다.
- 필터와 입력의 각 채널을 곱해서 나온 3개의 결과를 합산해서 하나의 출력값을 만들게 된다.
1️⃣ 예제 코드 - 다중 채널 컨볼루션
import numpy as np
import matplotlib.pyplot as plt
# RGB 이미지 예시
rgb_image = np.random.rand(32, 32, 3) # 32x32 컬러 이미지
filters = np.random.randn(3, 3, 3, 16) # 16개의 3x3 필터
# 정보 출력: 필터의 차원 정보
print(f"필터 모양: {filters.shape}")
print("필터의 의미:")
# rgb_image 의 각 채널에 대한 기준치 행렬
# 예시 : filters[:, :, 0, 0] : 빨간색 채널에 대한 기준치 행렬
# 예시 : filters[:, :, 1, 0] : 초록색 채널에 대한 기준치 행렬
# 예시 : filters[:, :, 2, 0] : 파란색 채널에 대한 기준치 행렬
# 총 16개의 필터가 있으므로
# 16개의 필터가 있으므로 16개의 출력 채널이 생성됨
# 실제 응용
# 다양한 채널로 인해을 받아 다양한 특징을 추출할 수 있음
# 이를 계층적으로 쌓아서 더 복잡한 특징을 추출할 수 있음
# 다중 채널 컨볼루션
def convolution_3d(image, filters, stride=1, padding=0):
"""
3D 컨볼루션 (다중 채널 입력, 다중 필터)
"""
K, _, _, C_out = filters.shape
# K : 커널의 높이
# C_out : 커널의 출력 채널 수
image = np.pad(image, ((padding, padding), (padding, padding), (0, 0)))
H_padded, W_padded, C_in = image.shape
out_H = (H_padded - K) // stride + 1
out_W = (W_padded - K) // stride + 1
output = np.zeros((out_H, out_W, C_out))
for f in range(C_out): # 각 출력 채널
for i in range(out_H):
for j in range(out_W):
h_start = i * stride
h_end = h_start + K
w_start = j * stride
w_end = w_start + K
# 모든 입력 채널에서 연산 후 합
region = image[h_start:h_end, w_start:w_end, :]
output[i, j, f] = np.sum(region * filters[:, :, :, f])
return output
padding = (filters.shape[0] - 1) // 2
feature_maps = convolution_3d(rgb_image, filters, padding=padding)
print(f"입력: {rgb_image.shape} -> 출력: {feature_maps.shape}")
# 시각화
plt.figure(figsize=(15, 5))
# 원본 이미지
plt.subplot(1, 3, 1)
plt.title("Original RGB Image")
plt.imshow(rgb_image)
# 첫 번째 필터의 첫 번째 채널 (3x3)
plt.subplot(1, 3, 2)
plt.title("First Filter (1st channel)")
plt.imshow(filters[:, :, 0, 0], cmap='gray') # 첫 번째 필터의 첫 번째 입력 채널
# 컨볼루션 결과의 첫 번째 채널
plt.subplot(1, 3, 3)
plt.title("First Feature Map")
plt.imshow(feature_maps[:, :, 0], cmap='gray') # 첫 번째 출력 채널
plt.tight_layout()
plt.show()
# 추가: 여러 필터들과 feature maps 시각화
plt.figure(figsize=(16, 8))
# 첫 번째 행: 여러 필터들 표시 (처음 4개)
for i in range(4):
plt.subplot(2, 4, i+1)
plt.title(f"Filter {i+1} (1st channel)")
plt.imshow(filters[:, :, 0, i], cmap='gray')
plt.axis('off')
# 두 번째 행: 해당 필터들의 feature maps 표시
for i in range(4):
plt.subplot(2, 4, i+5)
plt.title(f"Feature Map {i+1}")
plt.imshow(feature_maps[:, :, i], cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.show()[결과 예시]
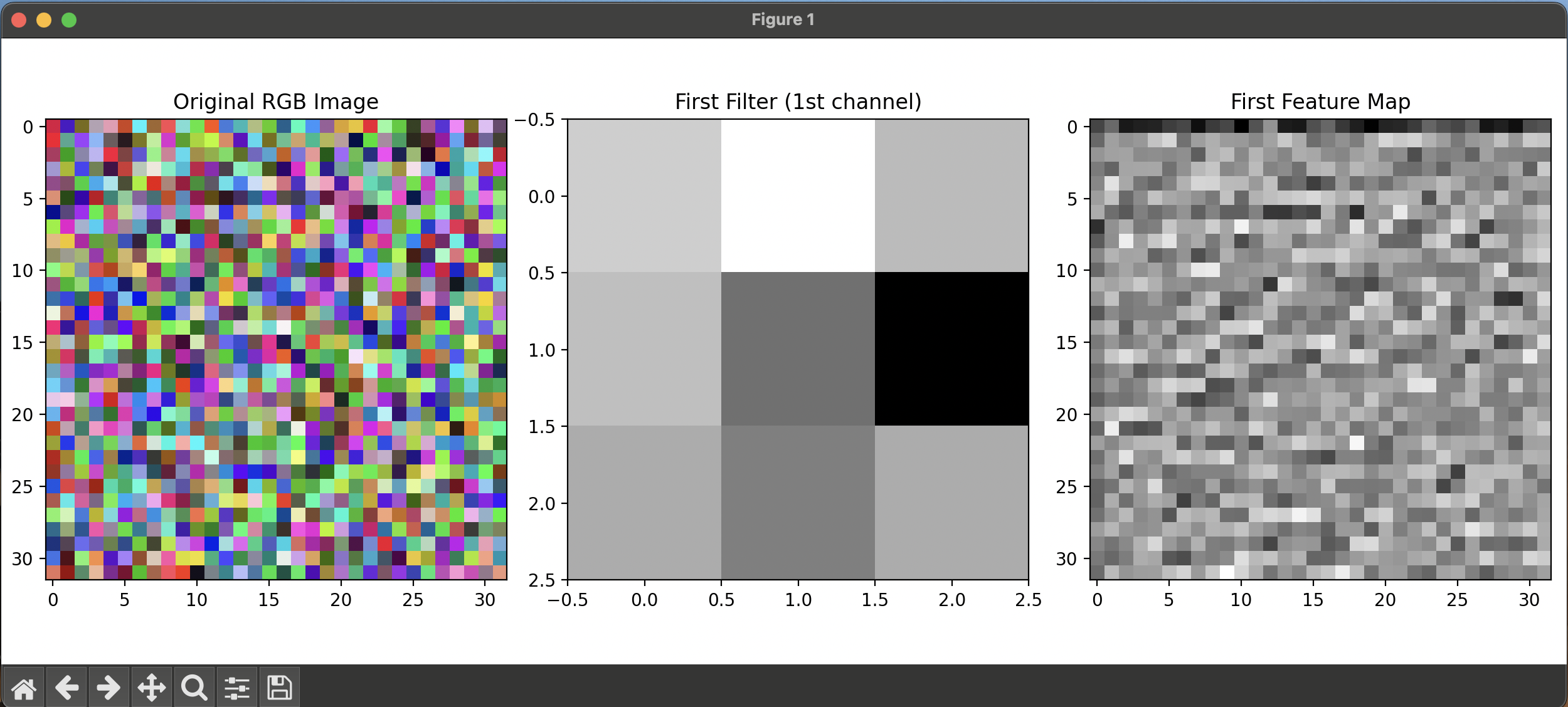

[코드 설명]
- 32 ×32 RGB 이미지에 16개의 3 ×3 필터를 적용하여, 각 필터가 RGB 3채널을 모두 고려해 하나의 특징맵을 생성한다.
- 필터가 이미지 위를 슬라이딩하면서 해당 영역과 원소별 곱셈 후 모든 채널의 결과를 합산하는 과정이며, 최종적으로 16개의 서로 다른 특징맵을 출력한다.
- CNN(Convolutional Neural Network)의 기본 원리로, 각 필터가 엣지, 텍스처 등 다양한 특징을 감지하는 역할을 한다.
⚙️ 요약 정리
- 컬러 이미지는 3 채널(RGB)이므로 필터도 3 채널로 구성됨.
- 필터는 각 채널을 독립적으로 처리한 후 출력값을 합산하여 하나의 특징맵을 생성함.
- CNN의 실제 구현은 Conv2D(filters=32, kernel_size=(3,3),...)과 같이 32개의 다양한 필터를 동시에 학습하도록 구성함.
✅ 풀링(Pooling)
1️⃣ 정의
특징맵(feature map)의 크기를 줄이는 연산으로, 중요한 정보는 유지하고 덜 중요한 정보는 버림.
🔹 필요 이유
- 연산량 감소
- 과적합 방지
- 위치 변화에 대한 불변성 증가 (예: 고양이 위치가 바뀌어도 인식 가능)
2️⃣ 주요 종류
| 종류 | 설명 | 예시 |
| Max Pooling | 영역 내 최댓값을 선택 | 선명한 특징 추출 |
| Average Pooling | 영역 내 평균값 선택 | 부드러운 특징 추출 |
3️⃣ 풀링(Pooling) 예시
입력 4x4 행렬에 대해 2x2 Max Pooling을 적용한다.
입력
[[1, 3, 2, 4],
[5, 6, 1, 2],
[7, 8, 3, 1],
[4, 2, 0, 5]]2x2 Max Pooling 결과
- 영역 1: [[1, 3], [5, 6]] → max = 6
- 영역 2: [[2, 4], [1, 2]] → max = 4
- 영역 3: [[7, 8], [4, 2]] → max = 8
- 영역 4: [[3, 1], [0, 5]] → max = 5
→ 출력:
[[6, 4],
[8, 5]]
4️⃣ 코드 실습 (MaxPooling)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_sample_image
# 샘플 이미지 로드
image = load_sample_image("flower.jpg")
# sklearn 에서 제공하는 샘플 이미지 로드
# 이미지 크기 : 427x640x3 (높이, 너비, 채널)
# 이미지 로드
# image = plt.imread("image.jpg")
gray_image = np.mean(image, axis=2) # 그레이스케일 변환
print(f"원본 이미지 크기: {gray_image.shape}")
# 이미지에 풀링 적용
def max_pooling_2d(input_array, pool_size=(2, 2), stride=2):
"""
2D 최대 풀링 구현
Args:
input_array: 입력 배열 (H, W)
pool_size: 풀링 윈도우 크기
stride: 스트라이드
Returns:
풀링된 배열
"""
h, w = input_array.shape
pool_h, pool_w = pool_size
# 출력 크기 계산 (패딩 없다고 가정)
out_h = (h - pool_h) // stride + 1
out_w = (w - pool_w) // stride + 1
# 출력 배열 초기화
output = np.zeros((out_h, out_w))
# 풀링 연산 수행
for i in range(out_h):
for j in range(out_w):
# 현재 윈도우 영역
h_start = i * stride
h_end = h_start + pool_h
w_start = j * stride
w_end = w_start + pool_w
# 2x2 풀링 윈도우 영역
# 2간씩 이동하여 최댓값 선택
# 4x4 이미지에 2x2 풀링 적용 시
# 첫번째 윈도우 : 0~1행, 0~1열
# 두번째 윈도우 : 0~1행, 2~3열
# 세번째 윈도우 : 2~3행, 0~1열
# 네번째 윈도우 : 2~3행, 2~3열
# 최댓값 선택
window = input_array[h_start:h_end, w_start:w_end]
output[i, j] = np.max(window)
return output
pooled_image = max_pooling_2d(gray_image, pool_size=(4, 4), stride=4)
print(f"풀링 후 이미지 크기: {pooled_image.shape}")
# 시각화
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].imshow(gray_image, cmap='gray')
axes[0].set_title(f'원본 이미지 ({gray_image.shape})')
axes[0].axis('off')
axes[1].imshow(pooled_image, cmap='gray')
axes[1].set_title(f'4x4 최대 풀링 ({pooled_image.shape})')
axes[1].axis('off')
plt.tight_layout()
plt.show()
# 크기 비교
print(f"데이터 크기 감소: {gray_image.size} → {pooled_image.size}")
print(f"압축률: {pooled_image.size / gray_image.size:.2%}")
[결과 예시]



4x4 윈도우를 4픽셀씩 이동(stride=4)하며 최댓값만 추출하도록 함수를 구현하였다. 풀링(Pooling)의 전과 후를 비교한 사진 결과는 위와 같으며, 풀링은 가장 큰 픽셀 값만을 선택하기 때문에, 디테일이 사라지고 픽셀이 뚜렷하게 나뉘는 블록 형태가 나타나는 것이 자연스러운 결과라고 할 수 있다.
또 427x640 크기의 꽃 이미지에 대해 4x4 최대 풀링을 적용해 약 1/16 크기로 축소된 특징 요약 이미지를 생성한 것을 수치로도 확인할 수 있었다.
5️⃣ 풀링의 효과
| 효과 | 설명 |
| 차원 축소 | 입력 크기 줄이기 (예: 28x28 → 14x14) |
| 과적합 방지 | 뉴런 수 감소로 모델 복잡도 ↓ |
| 연산 효율 향상 | 파라미터, 메모리, 속도 측면에서 유리 |
| 위치 불변성 | 물체 위치 변화에 강건함 |
⚙️ 요약
- 풀링은 중요한 특징만 남기고, 나머지를 줄이기 위한 과정
- 주로 MaxPooling(가장 큰 값 선택) 이 사용됨
- 위치에 따른 특징 이동에 강건한 모델을 만들 수 있음
- 연산량, 메모리 절약 → 속도 개선
✅ CNN 아키텍처
CNN은 크게 두 개의 블록으로 나뉜다.
| 블록 종류 | 구성 요소 | 주요 기능 |
| 특징 추출 블록 | Conv + ReLU + Pool | 의미 있는 패턴 추출 |
| 분류기(Classifier) | Flatten + Dense + Softmax | 추출된 특징을 클래스로 분류 |
1️⃣ 특징 추출 블록 (Feature Extraction Block)
구성 흐름
입력 이미지 → Conv → ReLU → (BatchNorm) → Pool → Conv → ...각 요소 역할
| 요소 | 역학 |
| Conv2D | 필터로 특징 추출 |
| ReLU | 비선형성 부여 (음수 제거) |
| BatchNorm (선택) | 학습 안정화, 수렴 가속 |
| Pooling | 차원 축소, 위치 불변성 확보 |
2️⃣ 분류기 (Classifier)
[흐름]
Conv 출력 (3D) → Flatten → Dense → Dropout → Dense(num_classes) → Softmax[구성 요소 설명]
| 구성 요소 | 역할 |
| Flatten | 2D 특징맵을 1D 벡터로 변환 |
| Dense(512) | 특징 조합 및 고수준 표현 |
| Dropout(0.5) | 일부 뉴런을 무작위로 꺼서 과적합 방지 |
| Dense(num_classes) | 클래스별 점수 예측 |
| Softmax | 예측값을 확률로 변환 |
[예시: 클래스 확률]
[0.1, 0.7, 0.15, 0.05] → 2번째 클래스가 예측 결과
3️⃣ 배치 정규화 (Batch Normalization)
| 항목 | 설명 |
| 개념 | 각 배치마다 평균 0, 분산 1로 정규화 |
| 효과 | 학습 안정화, 수렴 속도 향상, 과적합 억제 |
| 위치 | 일반적으로 Conv → ReLU 전에 사용됨 |
⚙️ 요약 정리
| 구성 요소 | 설명 |
| Conv Layer | 이미지에서 특징 추출 |
| ReLU | 비선형 변환 |
| Pooling | 크기 축소, 일반화 향상 |
| Flatten | 3D → 1D 변환 |
| Dense | 분류 위한 예측 수행 |
| Dropout | 과적합 방지 |
| Softmax | 클래스 확률 출력 |
이렇게 CNN에 관련된 내용을 정리하며 학습해 보았다. 이 중 풀링(Pooling)이 어떤 개념인지가 잘 이해가 되지 않았다. 특히 '중요한 정보는 남기고, 덜 중요한 정보는 버린다'라고 풀링을 표현하기도 하는데, 여기서 정보가 중요한지, 덜 중요한지를 어떻게 판단하는지가 의문이었다. 그래서 풀링의 개념을 조금 더 찾아보았다.

결론적으로, 풀링(Pooling) 연산이 정보가 중요한지를 직접 이해해서 판단하는 것이 아니라는 것이다.
풀링은 '어떤 정보가 중요할지 CNN 전체 모델이 판단할 수 있도록 단순한 방식으로 정보를 축소"하는 도구라고 이해하는 것이 좋을 것 같다.
그리고 Max Pooling은 '가장 강하게 활성화된 값' = '가장 눈에 띄는 특징'으로 판단하게 되는 것이다.
지금까지 CNN에 대한 내용을 정리하며 학습해 보았다. AI에 대한 기초적인 개념을 익히기 위해 CNN을 학습했으니 OCR, 이미지 세그멘테이션 등의 내용으로 넘어가 볼 것이다.
본 후기는 [카카오엔터프라이즈x스나이퍼팩토리] 카카오클라우드로 배우는 AIaaS 마스터 클래스 (B-log) 리뷰로 작성 되었습니다.



