프로젝트를 시작하고 시간이 부족해 내용을 정리하지 못했어서 오랜만에 글을 작성하며 어떤 것들을 배우고 공부하고 있는지에 대해 작성해 보는 시간을 가져보려 한다. 프로젝트 마감이 2-3주 남짓 남았기에 현재 진행 중인 내용들을 정리해 보는 시간이 필요하다고 생각되는데 모든 내용을 한 번에 담기에는 어려움이 있기에 주제의 가장 중요한 CAPTCHA 기능 3가지 중 기본적인 기능에 대해 먼저 설명해보려 한다.
그 전에 진행하고 있는 프로젝트에 대해 먼저 간단히 설명하면, 캡챠 서비스를 API 형태의 SaaS 서비스로 사용자들에게 제공하도록 하는 프로젝트이다. 우리는 캡챠 서비스를 단계로 구분해 사용자들에게 제공하도록 기획하였다.
0단계로는 일반적으로 '로봇이 아닙니다' 문구의 체크박스를 클릭하는 캡챠 기능, 1단계로는 1장의 사진이 9개의 그리드(Grid)로 나뉘어 나온 후 '~~ 가 포함된 이미지를 모두 고르시오.'와 같은 캡챠 기능이다. 2단계와 3단계는 추후 글에서 마저 설명할 수 있도록 할 것이고, 이 글에서 설명하는 캡챠 기능은 1단계 캡챠이다.
1, 2, 3으로 나뉘어지는 단계는 0단계의 캡챠에서 Bot인지 일반 사람의 사용자인지의 가능성을 AI를 통해 점수를 매긴 후 점수에 해당하는 캡챠 기능을 사용자가 제공받게 된다. 0단계의 캡챠에서 사람일 가능성이 높다고 판단되면 1, 2, 3단계의 캡챠를 해결하도록 하지 않기도 한다. 그래도 이 중 가장 사람일 가능성이 높다고 판단되는 사용자들을 해당 1단계 캡챠를 해결하도록 하는 것이다.
✅ 모델 선정
우리는 사람일 가능성이 높은 사용자들은 어려운 캡챠 문제를 해결하도록해 사용자 경험을 안 좋게 만들 필요가 없다고 판단하여 대중적으로 많이 접해본 캡챠 형태의 문제를 제공하기로 하였다.
1단계 캡챠는 1장의 사진을 9개의 그리드(Grid)로 구분해 사용자에게 보여주고 특정 객체가 포함된 이미지를 고르도록 하기에 객체 탐지 모델을 사용해 그리드에 특정 객체가 포함되어 있는지를 확인하게 하고자 하였다. 그래서 사용할 데이터셋과 모델을 먼저 선정하였다. 데이터셋은 다들 많이 알고 있는 COCO Dataset을 이용하였고, YOLOv8s 모델을 사용하기로 결정하였다.
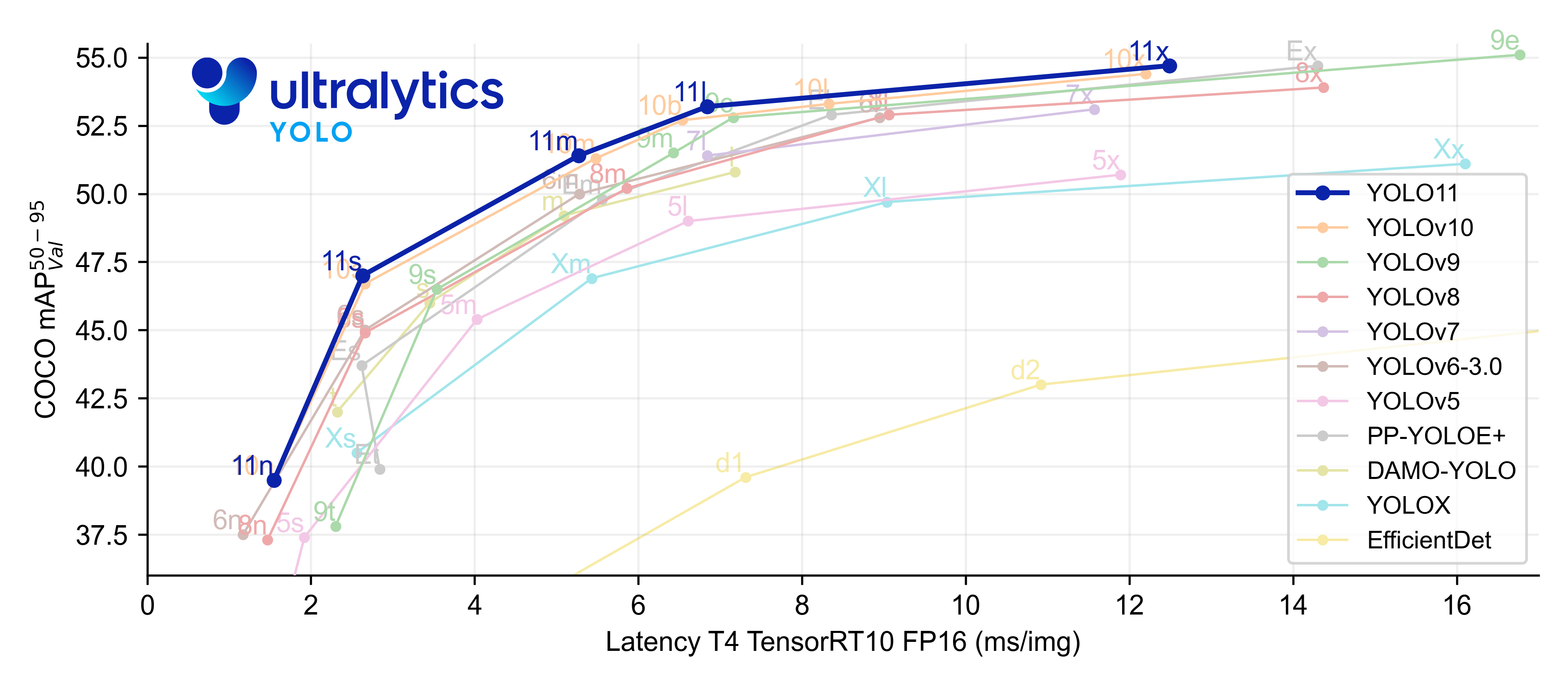
여러 후보 중 YOLOv8s를 선택하였는데, 아래의 이유들을 고려해보았다.
- 속도-정확도 균형: n < s < m < l 중 s(small)는 GPU/CPU 추론 모두 실용적
- 생태계 & 유지보수: Ultralytics의 yolo CLI/SDK로 학습·검증·내보내기(export)가 매우 단순
- 증강/스케줄 기본기: Mosaic/MixUp/Copy-Paste, Cosine LR 등 현대적 학습 기법이 기본 세팅
- 형상 다양성: ONNX/TorchScript/TensorRT 등 배포 포맷으로 쉽게 내보내기 가능
추후 모델의 학습 후 성능을 확인하고 기준치에 도달하지 못하였다고 판단해 YOLOv8n 모델로 최종 결정하였다.
✅ 데이터셋 (Dataset)
1️⃣ 클래스 선정
CAPTCHA 난이도/보편성을 고려해 아래와 같은 6개 클래스를 채택하였다.
person, car, dog, cat, bus, bicycle
2️⃣ COCO → YOLO 변환
- instances_train2017.json을 기준으로, 선택 클래스만 추출해 YOLO 텍스트 라벨 생성
- 이미지/라벨 1:1 매칭을 보장(라벨 없는 이미지 제외, 비이미지 파일(.npy) 정리)
3️⃣ 학습/검증 분할(데이터 누수 방지)
- 오버샘플링 리스트(train_oversampled.txt)를 쓰더라도 검증은 유니크 셋에서 샘플링
- 7:3 분할로 리스트 생성:
- train_split.txt (오버샘플 중 검증에 들어간 이미지는 제외)
- val.txt
COCO Dataset을 다운로드한 후 Train과 Validation으로 나눠진 원본 데이터를 확인해 보니 Train : Val = 95 : 5의 비율인 것을 볼 수 있었다. 그래서 Train과 Validation 데이터를 모두 합친 후 다시 Train : Val = 7:3의 비율로 분할하여 사용하였다.
✅ 학습 설정(Training Recipe)
프레임워크: Ultralytics YOLOv8 (PyTorch)
1️⃣ data.yaml
train: /data/vdb/datasets/yolo_dataset/train_split.txt
val: /data/vdb/datasets/yolo_dataset/val_unique.txt
nc: 6
names: [person, car, dog, cat, bus, bicycle]
data.yaml 코드 파일을 이용해 사용할 데이터, 클래스 명, 파라미터 설정 등을 명시한 후 학습 및 검증을 진행하였다. 아래와 같이 하이퍼 파라미터 설정을 통해 모델의 성능을 개선하고자 하였다.
2️⃣ 하이퍼 파라미터
- 모델: yolov8n.pt
- 해상도: imgsz=768
- 배치: batch=32
- 에폭: epochs=50 + EarlyStopping (patience=10)
- 옵티마이저: AdamW, lr0=0.0015, cos_lr=True, warmup_epochs=5
- 정규화: weight_decay=0.0007
- 증강: mosaic=0.5, mixup=0.05, copy_paste=0.05, close_mosaic=10 (마지막 10 에폭 모자이크 Off → 박스 정밀도↑)
✅ 평가 지표
1️⃣ 탐지 지표(Val)
- mAP@50 / mAP@50:95
- Precision / Recall / F1-score
- Confusion Matrix
- Latency(ms/img)
위와 같은 평가 지표들을 통해 모델이 얼마나 정확하게 객체들을 탐지하는지를 판단하였다. epoch을 반복하며 모델을 업데이트하는 기준은 mAP@50:95로 선정해 최종적으로 사용할 모델을 결정하였다.
2️⃣ CAPTCHA 지표(9 분할 과제)
- 타일 정답 기준: 타일 내부 최대 IoU가 τ_tile 이상 → 정답 타일
- 기본 τ_tile = 0.30 (객체 일부만 걸쳐도 정답 인정)
- 문항 통과 규칙(Strict):
- 정답 타일은 모두 선택 & 오답 타일은 하나도 선택하지 않음
또한 그리드(Grid)의 각 타일에 객체가 얼마나 겹쳐있는지 임계값을 지정하고 사용자는 정답 타일을 모두 선택해야 통과할 수 있도록 하였다.
프로젝트의 캡챠 서비스 기능 중 첫 번째인 1단계 캡챠에 대한 내용을 정리해 보았다. 캡챠 기획과 사용한 모델에 대한 내용이었다. 다음엔 2단계, 3단계 등에 사용한 모델 및 캡챠 기능에 대해 설명하고 프로젝트 전반에 대한 내용도 담을 수 있도록 해볼 예정이다.
진행 중인 프로젝트의 내용을 정리해 기록하지 않으면 오류를 발견하거나 맞는 방향으로 진행하고 있는지 확인하는 것이 부족할 수 있기에 이번 정리를 통해 이런 것들을 피드백하고 정리할 수 있었던 것 같다.



